But in practice deployment isn’t the end of the model’s life; it’s just the beginning, the first gate. We probably need to keep this model in production for a long time to achieve our goals.
Watch the Presentation
Original slides from the presentation are available here on GitHub, and video is now available on YouTube.
Annotated Slides
I’ve put together an annotated version of the presentation below. More details and a package demo are also available as a part of this website.
Congratulations, our model is in production!
… Now what do we do?
Our goal was to build a valuable model, and we’ve made a good start. Some enormous number of analytics projects are never deployed at all.
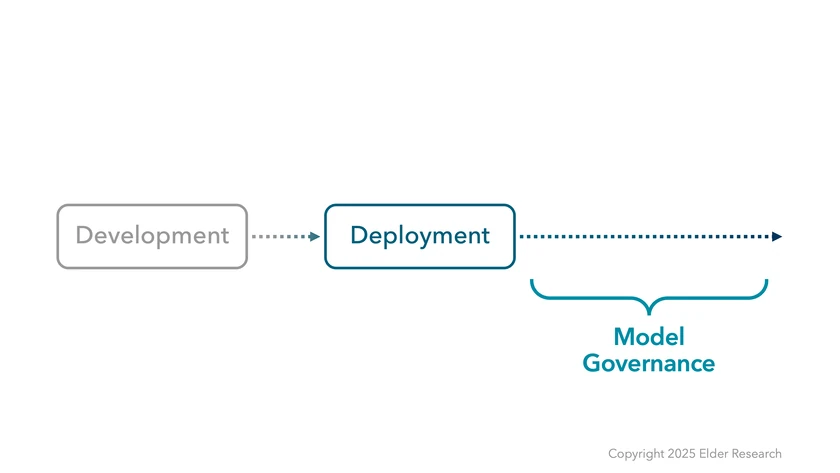
Typically, what happens after deployment falls under the rather stuffy heading of “model governance”: how do we keep the model running as things change?
Because a lot of things change! Dependencies can change. Sometimes production systems change. Or, maybe our model is so great that our business customer wants us to add to or retrain it. Either way, we’ll likely need to work with the model at some point in the future.
A lot of “governance” discussion focuses on the model itself: versioning, serving, monitoring, etc.
But in practice we often end up working with all of the “scaffolding” code that supports the model: how the model is trained, how the model is validated. And if we’re responsible for inference, there can be a lot of code involved there, too.
This talk comes from experiences we have had over the last few years putting a model into production and keeping it running. Early design decisions have large implications for a model’s future maintenance.

I have centered this talk on one question: What can we do now, while we’re building and designing the model, to make maintenance tasks easier later?
Looking back, I’ve distilled this experience into just a few foundational practices:
- Packaging
- Documentation
- Testing
- Writing legible code
On its face, this isn’t really a mind-blowing list. But in the governance context these practices go from “good things we probably should do” to bricks that stack on top of each other to build a foundation for our model.

This talk focuses on R because the project that inspired it was written in R—and because the R ecosystem has so many packages that make this process easier and more robust. But these ideas are applicable to Python, too!
We write a lot of Python code, and I’d be happy to talk about ways to apply these same principles with Python. Send me a message, and let me know you’re coming from this page.

So, let’s start with packaging
Packaging seems like the right place to begin because it’s foundational to everything else—even when we have no intentions of releasing anything on CRAN.
Our consulting work typically stays with our clients, housed in their internal systems, but packaging remains tremendously useful because packages provides the necessary structure to support maintenance over time and helps to automate many niggly details that come up. I use packages for just about every project I take on.
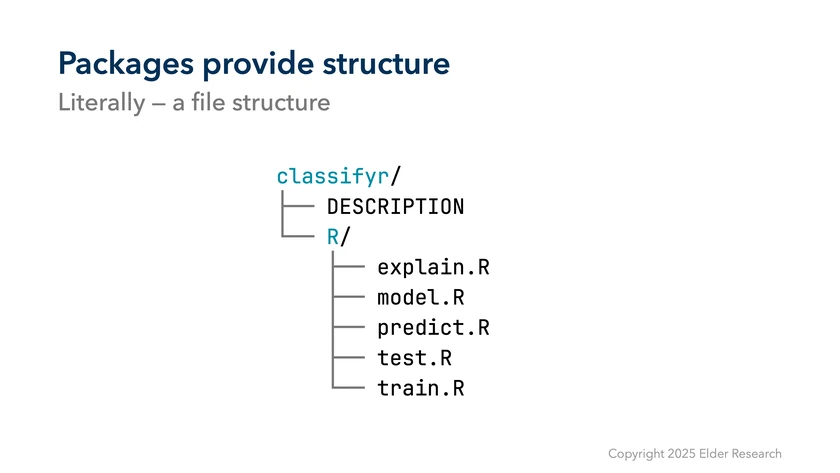
First, packages literally provide a file structure that dictates where source code, documentation, tests, and all kinds of others things should live.
This avoids the “many scripts in a folder” workflow that can be tough to keep working over time.

Package also provide a list of our dependencies in the DESCRIPTION file, laying out which packages (and versions of packages) are needed for all our functionality. This helps to codify what we need to deploy our model and its scaffolding in a repeatable way.

In addition to dependencies, DESCRIPTION includes key metadata, including authorship and version information. This matters because, in the governance context, we often need to identify both (1) the model being called and (2) the code used to train or predict from the model.

Packaging support automation, too, in conjunction with other packages in the ecosystem like devtools.
For example, the devtools package makes it simple to generate documentation for our package with one function call: devtools::document().

The devtools package also supports test discovery and execution via devtools::test().

devtools also provides more complex functionality like devtools::check(), which tests whether our package can be built and then loaded into a clean environment. If our package passes this check, it should be loadable and usable downstream.
This is especially useful in continuous integration or continuous deployment (CI/CD; for example, as part of a GitHub workflow that runs whenever changes are made to the codebase). Running these kinds of checks automatically means that people mostly don’t have to think about all the steps that go into making sure a codebase works.

Packaging also helps to make conventional R patterns available for models’ scaffolding code. R users expect to be able to call library() and use the functionality provided in the package; we don’t want to have to worry whether we are sourcing the correct files or that they are in an appropriate sequence.

Now, add documentation
Now we can build on our foundation by adding documentation. This is probably the least surprising part of the talk, but docs really are helpful—and they can offer support over a long time in multiple ways.

First, decent documentation is helpful across multiple time scales.
Most obviously, docs help whomever will be maintaining the model code over time, and this could very well be future you. Even if you are writing the code right now, in six or twelve months you probably won’t have all the details of the business problem or architecture at the top of mind; documentation really helps here.
But documentation also helps right now to get away from “vibes-based” programming and push us towards something more like a set of contracts: If I can write down what inputs my functions take and what outputs they should deliver then I’m forcing myself to think carefully about my system’s design. This will pay off later, both with testing and when it comes time to change something.
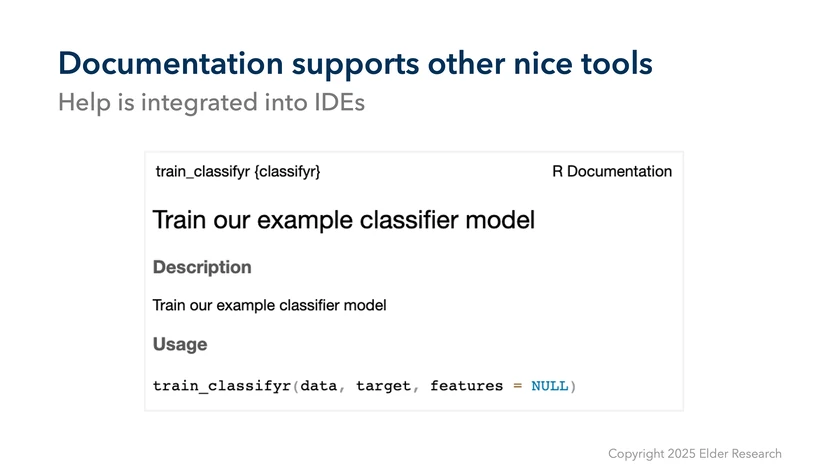
But there are also really nice quality-of-life factors that even basic documentation supports. If we are working in RStudio or Positron then we’re probably used to having nice documentation readily available. Providing our scaffolding code as a package with simple documentation (function titles, inputs, and outputs) is enough to make this help immediately available when writing or updating related code.

We also get nice things like inline autocompletion—even if we’re using pipes! And in a world with large language models and related tooling, these docs can provide helpful context.

And then there’s testing
For a long time, testing has been something I think I should do but didn’t really know why or how. I’m not an (official) software developer, and I didn’t go to school for computer science!
But in a data science context, production models is where testing is most obviously useful.

Tests provide a safety harness for making sure key parts of our work are correct and stay correct over time. I want something to catch me if I slip up!
Much like documentation, this is helpful in different ways at different times. Fist, does my code work right now? This again moves us away from vibes-based coding and towards a kind of contract written in code.
But even more importantly, what about later on—when packages we depend on are updated, we need to fix a bug, or we’d like to add functionality? It’s hard to keep all the relevant details in our heads so that a change we make in one part of the model or the code doesn’t affect things happening somewhere else. Tests can help to catch issues like this.

And it’s getting easier over time to write tests. If you haven’t done this before, I suggest to start small and then gow over time.We don’t have to boil the ocean.
To start, identify key functionality in your codebase. Maybe it’s model training, or inference, or a place where a merge happens and it can go wrong. Write a test—or a few tests—that capture what should be happening. Then, as bugs are found or new features are added, write simple tests to check for those bugs or to verify the new features.

And there are really good tools for this now, including testthat and its snapshots functionality. Snapshots, in particular, make it very easy to get started with testing. Over time, then, we can explore other ways of testing as needed.
Working with snapshots is a three-step process. First, start with some known (deterministic) data. In this example, I’m using the well-known Iris data set.
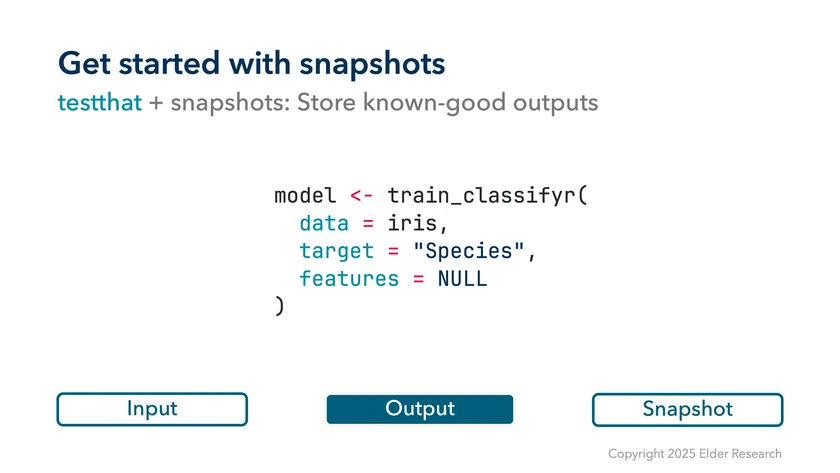
Next, capture the output of your function. Here, I’m testing a model output.

Finally, call testthat::expect_snapshot() with the result.
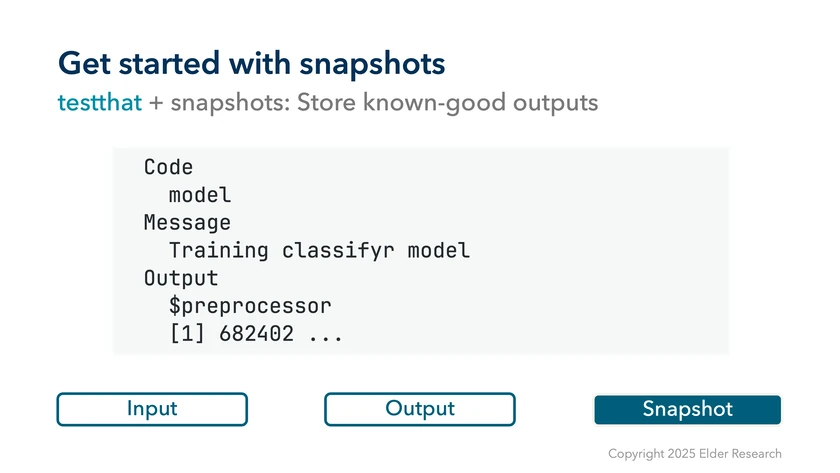
On the first call this will write a Markdown file into your package structure, storing what the call was, any messages, and the output.

In future calls, then, testthat will read that Markdown file and compare it with the output of the call.
I have found this to be useful for testing “interfaces” or other larger blocks of functionality. The key is that everything needs to be deterministic so that the output is the same every time; that’s a good practice!

Legible code as the icing on the cake
Will these three practices in place, our final step is to adopt a convention that help users better understand the code as they read through it.

This is particularly important with modeling packages, where the underlying “objects” we’re working with can be complicated.
Data can require cleaning and merging. Our “model” might, in fact, be a whole collection of models bundled together and depending on one another. We might be tasked with more than predicting simple values; our inference logic might become complex.
The project that inspired this talk, for example, included two trainable components, with one flowing into the other, and inference logic to support model explanations for stakeholders.

Lists and other collections offer one way to handle these kinds of complexity. Train our model(s), produce one or more lists of objects, and write custom functions to work with those.

There isn’t anything too wrong with that; such a workflow can be handled pretty cleanly if we take come care. Here, we extract the different parts of the model and then call a function that recombines them to make predictions.

But we already have a nice convention for how this works in R, through methods like predict(), print(), and friends. Regardless of how complex the object is, R users are used to calling methods like this to make things happen.
You might not know it, but these typically work using R’s S3 object system, and it’s really easy to adopt this ourselves in two steps.

First, instead of returning a simple list, return a structure with an extra class attribute. S3 is pretty informal, and we can name the class whatever we like, but sticking to something related to our project is nice.

Given that class name, we can write our own versions of print(), predict(), etc., immediately by tacking the class name onto the definition:
predict.classifyr_model <- function(x, ...)As soon as we do this, we’re back in the land of R model conventions. Users don’t have to know we have a custom model object or that our underlying code is complicated; they can call predict() like they always do and things will just work.
This is especially helpful when our scaffolding code is responsible for inference (predict()) or logging (print()). These simple definitions can make code more expressive and understandable later on.

If we want to, we can also extend this idea to entirely new methods: it just adds one more step.
Say, for example, we want to define a method called explain(). First, we make sure our objects have the right class; then, we define explain.classifyr_model(). Finally, we tell R that we have a new method to look for:
explain <- function(obj, ...) {
UseMethod("explain")
}That isn’t a stub or a pretend implementation; that’s the entire function body!
It’s easy to define these so that, when people come back to our code later, it’s expressive and understandable and follows the conventions of the ecosystem.

When we combine these principles together, it makes our models more maintainable over the long run.
In the case of the model that inspired this talk, we’ve been in production for a few years now for one of our clients. They are super happy with the model, and we’ve even survived a major transition from an Airflow-based architecture to Databricks. I have to think that this design, with the scaffolding code packaged and maintained, made this easier than it would have been otherwise.